Multi-field Adaptive Retrieval
- ICLR 2025 Spotlight
- 논문 링크
- 논문을 보기 전에 => Hybrid RRF & Hybrid CC, Hybrid Retrieval의 가중치. 아무 값이나 쓰고 있나요
- RAG 및 Information Retrieval에 대한 기본적인 이해가 필요합니다. (Dense Retrieval, Lexical Retrieval, BM25 및 임베딩 모델 등)
요약
- RAG에서 사용되는 많은 문서들은 특정한 메타데이터 (제목, 요약, 저자, 수정 날짜 등등)을 가지고 있다.
- 어떠한 메타데이터를 사용할 지는 사용자의 쿼리에 따라서 달라지게 될 것이다. 더불어, Dense Retrieval과 Lexical Retrieval 중 어떤 것에 더 가중치를 두어서 검색할 것인지도 사용자의 쿼리에 따라 그 중요도가 달라지게 된다.
- 이 논문에서는 어떤 메타데이터를 중요하게 여기고, 어떤 retrieval 방법론에 가중치를 두어서 검색을 수행할 것인지 사용자의 쿼리에 따라 동적으로 가중치를 변화하여 검색 성능을 증가시킨다.
- 해당 방법을 이용해 STaRK 데이터셋에 대하여 SOTA를 달성하였다.
간단한 배경 정리
기존 Hybrid Retrieval
기존에도 Hybrid Retrieval은 있었다. (참고 : Hybrid RRF & Hybrid CC)
하지만 어떤 query가 들어오든, 하나의 시스템에서 가중치는 전혀 변하지 않았다.
생각해보면, 어떤 query는 키워드 기반 검색이 더 잘 될 것이고, 어떤 query는 의미론적 기반 검색이 더 잘 될 것이다. 그렇지 않은가?
키워드가 뚜렷한 질문 -
2024년 KBO 리그에서 MVP를 수상한 사람은 누구입니까?
키워드가 뚜렷하지 않고, 의미론적 검색이 필요한 질문 -
작년에 한국에서 누가 제일 야구 잘했음?
위의 예시에서, 키워드가 뚜렷한 질문은 BM25와 같은 lexical retrieval, 의미론적 검색이 필요하면 임베딩 모델을 활용한 dense retrieval을 쓰는 것이 좋을 것이다.
그래서, 이 논문에서는 query에 따라서 어떤 검색 방법에 높은 가중치를 부여할 것인지 동적으로 판단한다.
RAG에 쓰이는 문서는 Unstructured인가 Semi-structured인가?
많은 경우에 RAG에 쓰이는 문서는 Unstructured라고 생각하는 경우가 대부분이다. 실제로 텍스트 더미를 vectorDB에 임베딩하고 검색하여 사용하는 것이 Retrieval의 가장 일반적인 (그리고 simple한) 예시이고, 이러한 단순한 텍스트 뭉치는 unstructured data이다.
하지만 실제로는 검색 성능을 높이기 위해서 metadata를 많이 활용한다. 테디님의 블로그에서도 찾아볼 수 있다.
이러한 metadata는 어떠한 'key'와 그 'key'에 따른 'value' 값으로 이루어진다. 즉, 문서의 메타데이터는 곧 어떠한 구조화된 형태를 지니게 된다. 이렇게 메타데이터를 포함한 문서들은 semi-strucutred 데이터라고도 볼 수 있다.
(물론 semi-structured 데이터에는 수많은 형태가 있다. csv 데이터나 HTML과 같이...)
그렇다면, 검색을 할 때에 어떠한 메타데이터를 사용해야 할까?
주로 RAG를 포함한 에이전트 시스템에서는, 입력한 query를 보고 agent가 어떠한 메타데이터를 사용해 검색을 할 지 판단하기도 한다.
하지만 이 논문에서는 이러한 에이전트 방식의 접근을 취하지 않고, 쿼리에 따라 각 메타데이터 간의 가중치를 예측하도록 한다.
논문에서는 'metadata'라는 용어 대신 'field'라고 사용하였다. 아무래도 metadata보단 어떠한 field라고 부르는 것이 더 일반화된 느낌이기에 이러한 용어를 선택한 것으로 보인다. 실제로도 논문에서 제안한 방식은 metadata 뿐만이 아니라 특정한 key-value 형태의 semi-structured 데이터에서 사용이 가능한 형태로 보인다. (단, value가 자연어)
그래서 앞으로 이 글에서도 metadata 대신 field를 사용하겠다.
mFAR : A Multi-Field Adaptive Retriever
논문에서 어떻게 여러 field와 scoring 방식 (lexical 혹은 dense) 중 어떤 것을 사용할지 동적으로 조정하였을까? 그 원리는 어렵지 않다 (진짜로)
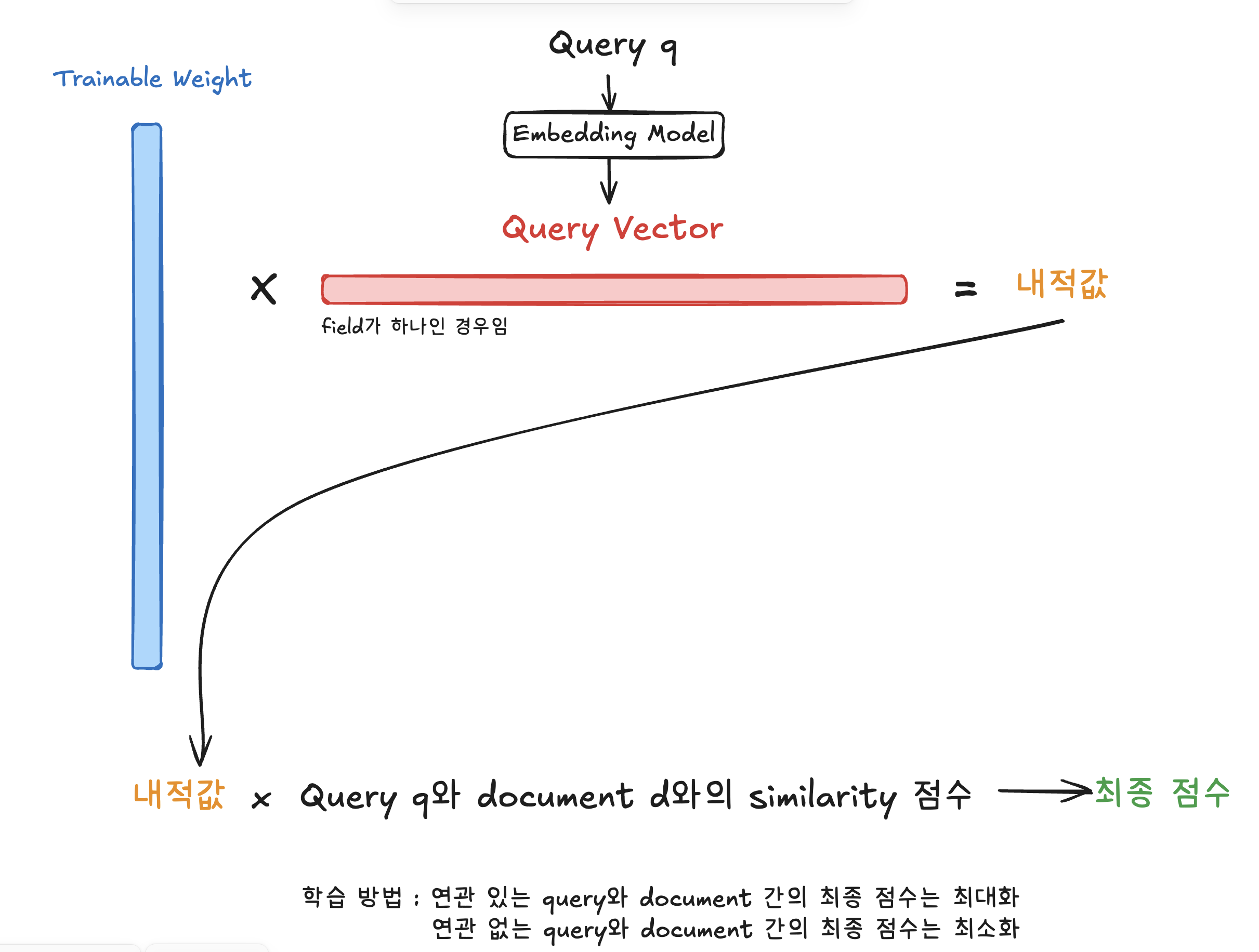
일단 말로 정리하자면 과정은 다음과 같다.
- 일단 query를 어떠한 임베딩 모델을 이용해 vector representation (임베딩 벡터)로 바꾼다.
- 'embedding size X field 개수' 만큼의 matrix를 준비한다. 이 matrix가 우리가 훈련할 weight이다.
- (weight와 query 임베딩 벡터의 내적) 곱하기 (lexical 혹은 dense retrieval의 점수)가 mFAR의 최종 점수가 된다.
- 이제 최종 점수를 토대로 contrastive loss를 사용해서 해당 matrix를 훈련한다.
contrastive loss를 사용하므로, 관련 있는 query와 document간의 최종 점수는 최대화하고, 관련 없는 query와 document 간의 최종 점수는 최소화해야 한다.
수식으로 다시 체크해볼까?
- query 와 document 에 대한 최종 점수 - 해당 retrieval에 존재하는 field들의 집합 - 해당 retrieval에서 사용하는 scoring 방식들. - query 와 document 에 포함된 field 의 값 에 대하여, 방법 의 retrieval score - 각 query, field, 방법 m에 대하여 계산된 weight.
이며, 는 query 의 임베딩 벡터, 은 학습 가능한 parameter가 된다. - 실제로 사용이 될때는 softmax 함수를 취하여
로 사용한다.
여기서
Normalize
다른 방법들(lexical or dense)의 retrieval들은 다른 score range를 가질 수 있다. 그래서 normalization이 필요하다. (참고 : Hybrid Retrieval의 가중치. 아무 값이나 쓰고 있나요)
이 논문에서는 따로 각 retrieval들을 normalization 하지 않고, batch normalization을 사용한다.
batch normalization을 쓰게 되면 거기서 파생되는 파라미터인
다만, 논문에서는 이 batch normalization을 사용한 normalization에 대한 효과는 명확하게 증명하지 않았으며, 그저 optional로 사용했다고 보면 된다. (학습시 grid search를 통해 가장 좋은 방식을 택했다고 한다)
Inference
당연하게도, 모든 filed와 모든 retrieval 방법의 모든 문서에 대한 score 계산은 너무 계산량이 많다. 그래서, 각 retrieval 방식과 각 field들에서의 top-k개의 문서들을 고르고, 해당 문서들에 대해서만 다른 retrieval 방식들의 점수를 계산하였다.
예를 들어서, lexical retrieval의 top 3개가 문서 A, B, C고, dense retrieval에서 top 3개가 문서 B, C, D라면, 추가로 문서 A의 dense retrieval 점수를 계산하고, 문서 D의 lexical retrieval 점수를 계산했다.
물론 hybrid retrieval에서, hybrid를 수행했더니 갑자기 문서 E가 실제 1등일 수 있다. 하지만 그럴 확률이 높지 않으므로, 인퍼런스 시에 각각 top-k개만 선택하는 전략은 타당한 근사 전략이다. AutoRAG의 hybrid retrieval에서도 같은 전략을 사용한다.
Loss function
학습에 쓰인 contrastive loss를 간단하게만 짚고 넘어가자.
기본적인 개념으로, 'positive pair'는 연관성 점수가 높게, 'negative pair'는 연관성 점수가 낮도록 훈련한다.
: 번째 query : query와 실제로 연관성이 있는 document : query와 관련 없는 document, 그리고 해당 document들의 집합 : query와 document 사이의 retrieval score (BM25 score, cosine similarity 등) : temperature 하이퍼 파라미터
수식을 보면, 연관있는 document 간의 score는 최대화하고 연관없는 document 간의 score는 최소화하는 방향으로 학습이 진행될 것이라는 것을 알 수 있다.
위는 query는 고정하고 document를 바꾸었다. document를 고정하고 query를 바꾸는 방식으로 훈련할 수도 있다. 이 두 loss를 합치면 bi-directional loss를 이용한다고 볼 수 있다.
최종 loss
실험과 결과
실험은 STaRK 데이터셋을 사용하여 진행되었다.
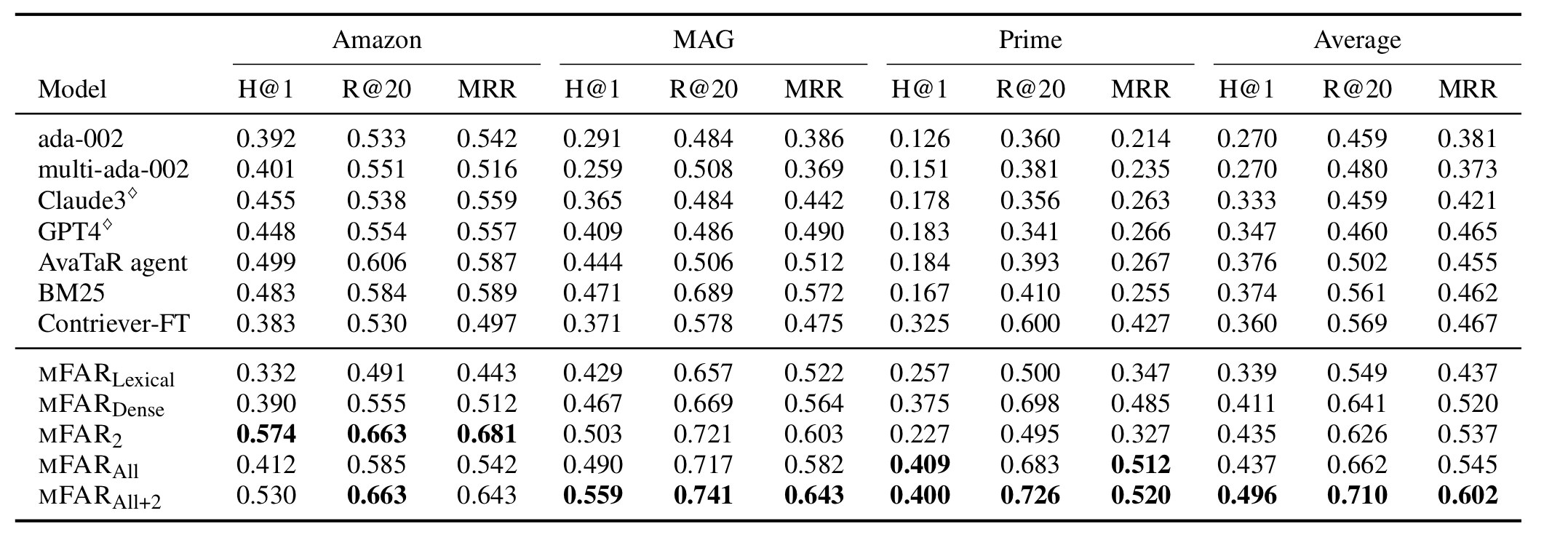
위의 mFAR 아래 첨자의 의미
| 이름 | Lexical | Dense | Single Field | Multi Field |
|---|---|---|---|---|
| Lexical | ✅ | ✅ | ||
| Dense | ✅ | ✅ | ||
| 2 | ✅ | ✅ | ✅ | |
| All | ✅ | ✅ | ✅ | |
| All+2 | ✅ | ✅ | ✅ | ✅ |
Multi-field가 더 좋을 때도 아닐 때도 있다.
Multi-field와 Single-field를 비교를 했을 때, Dense Retrieval에서는 multi-field가 효과적이었으나 Lexical Retrieval에서는 오히려 single-field가 점수가 높은 경우도 있었다.
('Amazon'에서 BM25와 mFAR_Lexical간의 비교)
('MAG'에서 Contriever-FT와 mFAR_Dense간의 비교)
BM25에서는 점수가 길이에 따라서 정규화된다 => 더 짧은 문서일수록 높은 점수를 받는 경향이 있다.
그런데 특정 필드는 아주 짧으면서도 반복적인 경향이 강할 수 있고, 그 반복이 꼭 높은 연관성을 의미하지 않을 수도 있다.
예를 들어서 '발행 기관'이라는 필드가 있다고 해보자. 해당 필드의 예상되는 값으로는 '한국인공지능협회', '한국인공지능보안학회', '한국장학재단' 등이 있을 수 있겠다.
그런데, 검색어가 '한국에서 가장 한국어를 잘하는 사람은 누구야?'였다면 '한국인공지능협회', '한국인공지능보안학회', '한국장학재단' 등의 BM25 연관 값은 꽤나 높게 나올 수 있다. 그러나 질문과 관련이 있을까? 단 1도 없다;;
그래서 논문에서는 이러한 상황에서, 필드 별 가중치를 조정하는 것이 어렵고 앞으로 풀어가야 하는 문제라고 지적하고 있다. 한 가지 대안으로는 'All+2'와 같이 single field와 multi field를 모두 사용하는 방식을 제안한다.
Hybrid 방식은 대체로 더 좋았다
실험 결과, 모든 데이터셋에서 하나의 방식을 쓰는 것보다는 hybrid를 쓰는 것이 더 높은 결과를 가져다 주었다.
Query별로 다른 가중치를 부여하는 방식이 과연 효과적인가?
query별로 다르게 학습한 것과, query와 관련없이 globally하게 학습한 상황을 간단하게 비교해보았더니, 아래와 같은 결과가 나왔다.

Loss를 보면 되는데, 작게는 7% 정도에서 크게는 40% 넘게 성능이 떨어진 모습을 보이고 있다.
Query에 따라서 가중치를 바꾸는 것은 아주 유의미한 성능 향상을 보여준다.
결론
- Hybrid 최고!
- Query에 adaptive한 Hybrid는 더 좋다!
- 어떤 metadata(field)를 사용할 지 query에 알맞게 골라주는 것도 유의미한 성능 향상이 있다.